
More than 252,000 new websites go live every day. This raises the question: how does Google even know these sites exist, let alone rank them? Do they manually check each one? Of course not. The answer is crawlers. But before we dive into how crawlers work, let’s know what crawlers are:
Contents
What are Search Engine Crawlers?
Search engine crawlers (also called spiders or bots) are automated programs that move through the web, following links, scanning content, and collecting data to understand what each page is about – so they can index and rank.
If a page isn’t crawled, it can’t be indexed.
And if it’s not indexed, it will never appear in search results.
That’s why knowing how search engine crawlers work is a foundation for getting visibility in Google.
Types of Google Crawlers You Should Know
When we hear ‘Googlebot,’ it sounds like a single bot. But Google has different versions of crawlers to crawl different types of content.
- Googlebot Desktop: Crawls your site as if the visitor were using a desktop browser.
- Googlebot Mobile: Crawls your site as if the visitor were on a smartphone
- Googlebot Images: Dedicated to image content.
- Googlebot Video: Focused on video indexing.
- Googlebot News: Crawls news publishers so articles appear quickly in Google News.
- AdsBot: Evaluates landing pages used in Google Ads campaigns.
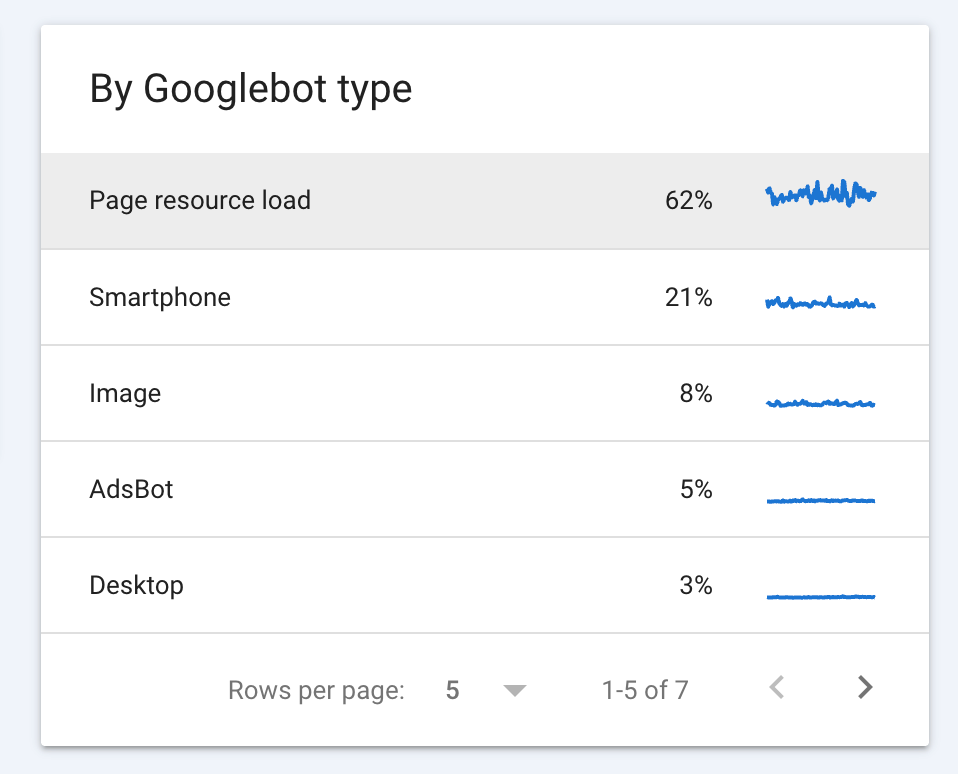
Pro Tip: Googlebot Mobile is the primary crawler that decides how your site ranks. So even if your desktop site is optimised, a slow mobile version will drag your rankings down.
Beyond these, Google also has speciality bots like Google-Site-Verification (to confirm site ownership) or Google-Read-Aloud (to help with accessibility). Now, let’s shift gears and see how the crawlers move through your site.
How Search Engine Crawlers Work (Step-by-Step Process)
How do crawlers move through your website? Here’s the breakdown:
- Seed URLs: Seed URLs can be your homepage, sitemaps, or backlinks. Crawlers enter your site through these links and use them as starting points to explore your site.
- Following Links: Once crawlers find your pages, they follow both internal links and external links. This helps them build a map of your site’s structure and understand which pages are more important.
- Crawl queues: Search engines use a crawl queue to prioritise which pages get fetched first. Updated, high-value, and well-linked pages usually get priority. On the other hand, slow loading or duplicate pages get pushed down the list and are crawled less often.
- Rendering: Bots also render pages to see how JavaScript and other dynamic elements load (essentially viewing the page as a user would). However, rendering is resource-heavy. So if your site relies heavily on JavaScript without proper fallback content, crawlers may struggle to process it fully or delay indexing.
The crawling process allows search engines to find, map, and process your site’s content. If each step works smoothly, your pages have a higher chance of being indexed and ranked accurately.
Robots.txt, Sitemaps, and Other Signals That Guide Crawlers
Crawlers don’t move randomly through your site; they follow signals that tell them what to crawl, what to skip, and how to read your content. These signals are an important part of how crawlers work and determine whether your priority pages get seen or ignored.
1. Robots.txt
The robots.txt file sits in the root directory of your site. It gives crawlers basic instructions on where they can go, which pages they should crawl, and which they should skip. It’s often used to block low-value sections like duplicate pages, sensitive areas, or internal search results. For example, you might disallow “/search/” URLurl so crawlers don’t waste time indexing on-site search result pages.
The flip side?
If misconfigured, robots.txt can also block important pages from being indexed.
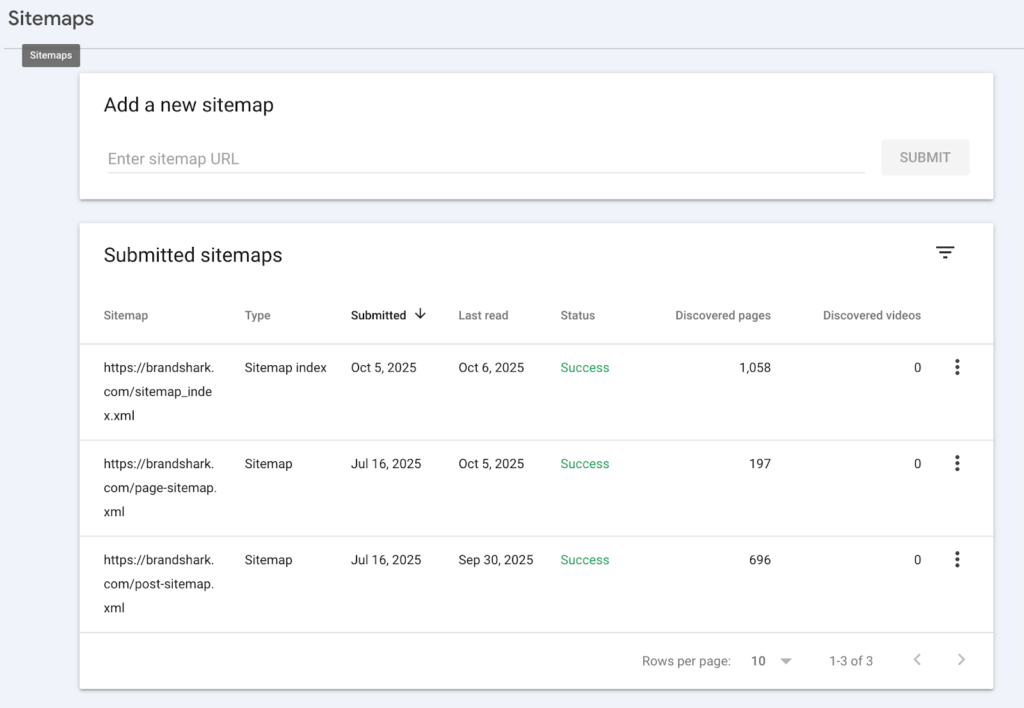
3. XML sitemaps
An XML sitemap is a file that has all the URLs on your site. It helps crawlers understand your site structure and makes key pages easier to find.
This is especially useful for large websites with thousands of pages, or for sites where some pages aren’t well linked internally. To make discovery even easier, you can submit your sitemap to GSC – so crawlers can locate and index your priority pages.
4. Internal linking
Crawlers use internal links to navigate your site and understand how pages are connected. A clear linking structure signals hierarchy.
For example: homepage → category → product. A key point to note is that pages without internal links get ignored. Why? Because crawlers have no direct path to reach them.
5. Structured data
Sometimes, along with the title and description, you also see details like star ratings or product prices. That’s structured data at work. It uses Schema.org markup to give search engines extra context about your page. You can apply different types of schema, such as product, article, event, or review. Now, note: adding schema doesn’t guarantee rich snippets, but it does improve your chances of standing out in search results.
Quick Tip: Before hitting publish, run your site through tools like Google Search Console’s URL Inspection and Rich Results Test. This way, you’ll see how crawlers interpret your signals – and catch issues before they cost you visibility.
Why Search Engine Crawling Is the Foundation of SEO
Each domain has a crawl budget. It means the number of pages bots will fetch within a timeframe. For small sites, crawl budget usually isn’t a problem. But for large or complex websites such as e-commerce platforms with thousands of product pages, crawl budget is critical. If bots waste their crawl budget on duplicate URLs or dead ends, your important revenue-driving pages may never be discovered or indexed.
Common Crawl Challenges
- Crawler traps: endless calendars, session IDs, or loops that keep bots stuck.
- Duplicate content: parameterised URLs or near-identical pages that waste crawl slots.
- Blocked resources: disallowing CSS or JavaScript can stop bots from loading and understanding your pages.
- Slow or broken servers: 404 errors and slow response times reduce how often crawlers return to your site.
Quick Wins to Fix Crawl Issues
- Clean up and simplify your URL structures.
- Improve internal linking so important pages are easy for crawlers to reach.
- Double-check robots.txt and meta directives to avoid blocking key pages.
- Consolidate duplicates with canonical tags.
- Speed up your site by compressing images, trimming bloat, or upgrading hosting.
Crawling directly affects whether your pages ever make it into search results. With the basics covered, the next step is to look at the signals that guide crawlers, which decide how effectively search engines interpret your site.
Best Tools to Monitor and Improve Website Crawling
At Brandshark, one of our mottos is: you can’t fix what you can’t measure. The same applies to crawling. To improve, you first need to see how search engines interact with your site. Luckily, a few tools make this possible by showing how crawlers view your pages and where issues exist.
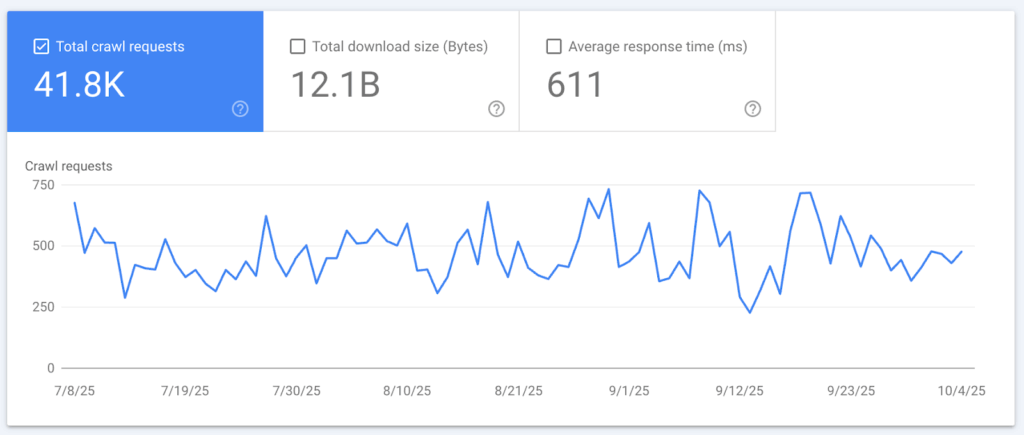
1. Google Search Console
GSC shows you how Google crawls and indexes your site. It provides crawl stats, coverage reports, and errors, so you can see which pages were found, which were indexed, and which were skipped with reasons.
2. Screaming Frog / Sitebulb
Screaming Frog is a desktop tool that crawls your site the way a search engine would. It helps you find broken links, duplicate content, missing meta tags, and blocked resources. This helps you catch errors ahead of time, instead of waiting for Google to flag them.
3. Log File Analysis
Log file analysis is about checking the raw server logs of your website. These logs record every request made to your server, including visits from search engine bots. By analysing them, you can see:
- Which bots visited your site (Googlebot, Bingbot, etc)
- How often they crawled your pages
- Which URLs did they access
- Any errors they hit while crawling (for example, 404 “page not found”)
The setup can be technical, but the insights are valuable for spotting wasted crawl budget, fixing errors, and making sure bots focus on the right pages.
Conclusion
Crawlers decide whether your pages get discovered, indexed, and ranked. If they can’t reach or process your content, it won’t show up in search results. By knowing how crawlers work, you can take the right steps: clean site structures, proper signals, and the right tools go a long way in making your site crawler-friendly.
At Brandshark, a digital marketing agency in Bangalore, we help businesses strengthen their SEO so that search engines can easily find, understand, and rank their content so it reaches the right audience. Get in touch with us today.
